









مقدمه
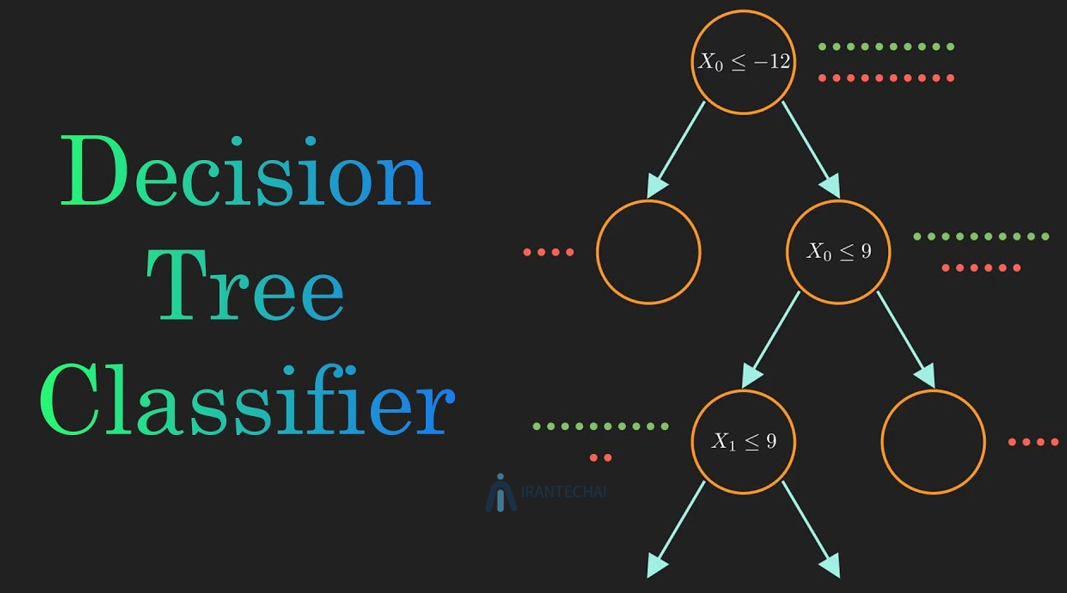
الگوریتم درخت تصمیم (Decision Tree) یک روش یادگیری ماشین است که برای دسته بندی و پیش بینی استفاده میشود. این الگوریتم یک مدل شبیه به نمودار درختی ایجاد میکند که به کمک آن میتوان تصمیمگیری و یا نتایج را پیشبینی کرد. هدف استفاده از الگوریتم درخت تصمیم، ایجاد یک مدل پیش بینیکننده است که بتواند دادهها را به دستههای مختلف تقسیم و یا مقادیر خروجی را پیش بینی کند. این الگوریتم به صورت یک ساختار درختی عمل میکند که هر گره داخلی یک سؤال یا شرط مربوط به ویژگیهای دادهها را نشان میدهد و هر گره برگ نتیجه نهایی یا پیشبینی را. در ادامه این مقاله قصد داریم به بررسی اینکه الگوریتم درخت تصمیم چیست و چه کاربردهایی دارد، بپردازیم. پس برای کسب اطلاعاتی بیشتر در این زمینه با ما همراه شوید.
فهرست
الگوریتم درخت تصمیم چیست؟
مزایا و معایب استفاده از الگوریتم درخت تصمیم چیست؟
درخت تصمیم چه نقشی در الگوریتم random forest ایفا میکند؟
پیگیری اخبار هوش مصنوعی و فناوری های وابسته به آن
الگوریتم درخت تصمیم چیست؟
الگوریتم درخت تصمیم (Decision Tree) یکی از الگوریتمهای محبوب و پرکاربرد در حوزه یادگیری ماشین و داده کاوی است که برای مسائل طبقه بندی (Classification) و رگرسیون (Regression) استفاده میشود. این الگوریتم به دلیل ساختار ساده و قابل فهم آن، به راحتی قابل تفسیر است. در ادامه به توضیح ساختار و کاربرد یک درخت تصمیم میپردازیم:
ساختار درخت تصمیم
- گره ریشه (Root Node): اولین گره درخت است که شامل کل مجموعه دادهها میشود.
- گرههای داخلی (Internal Nodes): گرههایی هستند که دادهها را بر اساس ویژگیهای مختلف تقسیم میکنند.
- گرههای برگ (Leaf Nodes): گرههایی که نشان دهنده تصمیم نهایی یا خروجی هستند.
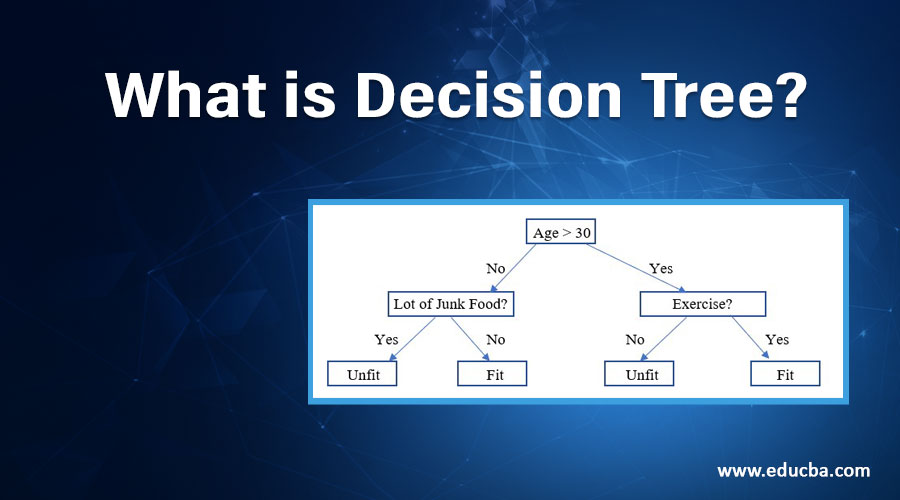
کاربرد درخت تصمیم
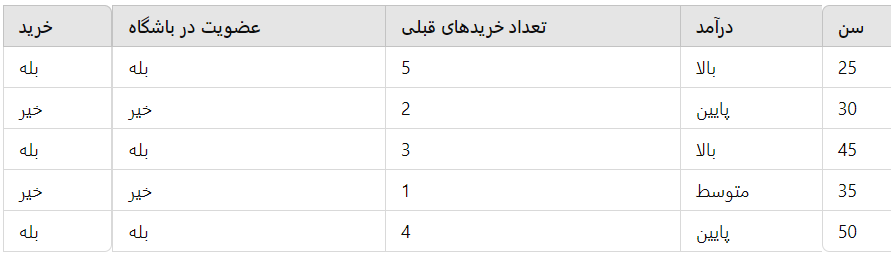
برای توضیح کامل کاربرد الگوریتم درخت تصمیم، یک مثال ساده و عملی را بررسی میکنیم. فرض کنید که میخواهیم پیشبینی کنیم که آیا یک مشتری در آینده یک محصول خاص را خریداری خواهد کرد یا خیر. دادههای ما شامل ویژگیهای مشتریان مانند سن، درآمد، تعداد خریدهای قبلی و عضویت در باشگاه مشتریان است. هدف ما این است که با استفاده از درخت تصمیم، مدلی بسازیم که بتواند پیشبینی کند آیا یک مشتری جدید محصول ما را خواهد خرید یا نه. فرض کنید دادههای ما به صورت زیر است:
مراحل ساخت درخت تصمیم
انتخاب ویژگی: ابتدا باید تصمیم بگیریم که کدام ویژگی بهترین تقسیم بندی را ایجاد میکند. برای این کار از معیارهایی مانند کسب اطلاعات (Information Gain) استفاده میکنیم. فرض کنید که بعد از محاسبات، مشخص میشود که ویژگی “درآمد” بهترین ویژگی برای تقسیم بندی اولیه است. سپس دادهها را بر اساس ویژگی “درآمد” به سه گروه بالا، متوسط و پایین تقسیم میکنیم. با توجه به تقسیم بندی های انجام شده برای هر گروه، فرآیند را تکرار میکنیم تا به تصمیم نهایی برسیم. در نتیجه درخت تصمیم نهایی ممکن است به صورت زیر باشد:
درآمد
/ | \
بالا متوسط پایین
/ | \
بله خیر تعداد خریدهای قبلی
/ \
> 3 <= 3
/ \
بله عضویت در باشگاه
/ \
بله خیر
/ \
بله خیرکاربرد عملی
با استفاده از این درخت تصمیم، میتوانیم به سادگی پیشبینی کنیم که آیا یک مشتری جدید محصول ما را خریداری خواهد کرد یا خیر. به عنوان مثال، اگر یک مشتری جدید با مشخصات زیر داشته باشیم:
سن: 40
درآمد: پایین
تعداد خریدهای قبلی: 2
عضویت در باشگاه: بله
بر اساس درخت تصمیم، این مشتری محصول را خریداری خواهد کرد، زیرا درآمد پایین دارد، تعداد خریدهای قبلی کمتر از 3 است و عضو باشگاه است.
مزایا و معایب استفاده از الگوریتم درخت تصمیم چیست؟
مزایا
- سادگی و تفسیرپذیری: درختهای تصمیم به راحتی قابل فهم و تفسیر هستند. حتی افراد بدون تخصص در یادگیری ماشین میتوانند ساختار درخت و تصمیمهای گرفته شده را درک کنند.
- عدم نیاز به آماده سازی پیچیده اطلاعات: درختهای تصمیم نیاز به نرمال سازی یا استاندارد سازی دادهها ندارند. همچنین میتوانند با دادههای گمشده به خوبی کار کنند.
- مدیریت دادههای گمشده: درختهای تصمیم میتوانند به طور طبیعی با دادههای گمشده مقابله کنند و نیازی به پر کردن مقادیر گمشده ندارند.
- کارآیی بالا در دادههای بزرگ: درختهای تصمیم به دلیل ساختار سلسله مراتبی خود میتوانند به صورت کارآمدی دادههای بزرگ را پردازش کنند.
- توانایی مدیریت دادههای عددی و دستهای: درختهای تصمیم میتوانند هم با دادههای عددی (پیوشته) و هم با دادههای دستهای (گسسته) کار کنند.
معایب
- مشکل بیشبرازش (Overfitting): درختهای تصمیم ممکن است بیش از حد به دادههای آموزش وفادار باشند، به ویژه اگر عمق درخت زیاد باشد. این مشکل میتواند باعث شود مدل روی دادههای جدید عملکرد ضعیفی داشته باشد. برای مقابله با این مشکل از تکنیکهایی مانند هرس کردن (Pruning) استفاده میشود.
- حساسیت به دادههای نویزی: درختهای تصمیم ممکن است نسبت به دادههای نویزی یا دادههای غیر مربوط حساس باشند، که میتواند باعث کاهش دقت مدل شود.
- عدم پایداری: تغییرات کوچک در دادهها میتواند به تغییرات بزرگی در ساختار درخت منجر شود، که این امر باعث عدم پایداری مدل میشود. روشهایی مانند استفاده از جنگل تصادفی (Random Forest) میتوانند این مشکل را کاهش دهند.
- محدودیت در مدل سازی روابط غیرخطی پیچیده: درختهای تصمیم ممکن است در مدل سازی روابط غیر خطی بسیار پیچیده بین ویژگیها و متغیر هدف ناتوان باشند. مدلهای پیچیدهتر مانند شبکههای عصبی یا ماشینهای بردار پشتیبان (SVM) ممکن است در این موارد عملکرد بهتری داشته باشند.
درختهای تصمیم ابزار قدرتمندی برای بسیاری از مسائل یادگیری ماشین هستند، به ویژه زمانی که نیاز به مدلهای ساده و قابل تفسیر داریم. با این حال، برای جلوگیری از مشکلاتی مانند بیشبرازش و ناپایداری، ممکن است نیاز به استفاده از تکنیکهای تکمیلی مانند هرس کردن یا مدلهای ترکیبی مانند جنگل تصادفی داشته باشیم. انتخاب الگوریتم مناسب بستگی به ویژگیهای دادهها و نیازهای خاص مسئله دارد.
درخت تصمیم چه نقشی در الگوریتم random forest ایفا میکند؟
الگوریتم درخت تصمیم نقش اساسی در ساختار و عملکرد الگوریتم جنگل تصادفی (Random Forest) ایفا میکند. جنگل تصادفی مجموعهای از درختهای تصمیم است که به صورت همزمان برای حل یک مسئله یادگیری ماشین به کار میروند. در ادامه به تفصیل نقش الگوریتم درخت تصمیم در جنگل تصادفی و نحوه عملکرد آن را توضیح میدهیم:
جنگل تصادفی (Random Forest)
جنگل تصادفی یک الگوریتم یادگیری جمعی (Ensemble Learning) است که از ترکیب چندین درخت تصمیم استفاده میکند تا دقت و پایداری مدل را افزایش دهد. این الگوریتم بهویژه برای مسائل طبقه بندی (Classification) و رگرسیون (Regression) مفید است.
نحوه عملکرد جنگل تصادفی
نمونهگیری تصادفی با جایگزینی (Bootstrap Sampling): ابتدا، چندین زیر مجموعه تصادفی از دادههای آموزش با جایگزینی انتخاب میشوند. هر زیرمجموعه به اندازه مجموعه دادههای اصلی یا کمتر است.
ساخت درختهای تصمیم: برای هر زیر مجموعه، یک درخت تصمیم به طور مستقل ساخته میشود. در اینجا همان الگوریتم درخت تصمیم به کار میرود، اما با یک تفاوت کلیدی!
در هر گره، به جای استفاده از همه ویژگیها برای انتخاب بهترین تقسیم بندی، تنها یک زیرمجموعه تصادفی از ویژگیها انتخاب میشود. این کار باعث کاهش همبستگی بین درختها و افزایش تنوع مدل میشود.
ترکیب نتایج: برای طبقه بندی، نتیجه نهایی با رأی گیری اکثریت از نتایج تمام درختهای تصمیم تعیین میشود. برای رگرسیون، نتیجه نهایی میانگین خروجیهای تمام درختها است.

مزایای استفاده از درختهای تصمیم در جنگل تصادفی
کاهش بیش برازش (Overfitting): استفاده از مجموعهای از درختهای تصمیم به جای یک درخت منفرد باعث کاهش احتمال بیش برازش میشود. این امر به ویژه زمانی که دادهها نویزی هستند یا تعداد ویژگیها زیاد است، مفید است.
پایداری و دقت بالاتر: ترکیب نتایج چندین درخت تصمیم باعث افزایش دقت و پایداری مدل میشود. حتی اگر یک درخت تصمیم دقت پایینی داشته باشد، نتیجه نهایی با استفاده از مجموعهای از درختها بهبود مییابد.
کاهش حساسیت به دادههای نویزی: جنگل تصادفی به دلیل ترکیب نتایج چندین درخت تصمیم، حساسیت کمتری به دادههای نویزی دارد و میتواند از تأثیر منفی دادههای نویزی بکاهد.
الگوریتم درخت تصمیم نقش محوری در ساختار و عملکرد جنگل تصادفی دارد. در واقع، جنگل تصادفی از مزایای چندین درخت تصمیم بهرهبرداری میکند تا یک مدل قویتر، پایدارتر و دقیقتر ایجاد کند. استفاده از نمونهگیری تصادفی دادهها و ویژگیها در هر درخت تصمیم، باعث افزایش تنوع و کاهش همبستگی بین درختها میشود که این امر بهبود قابل توجهی در عملکرد مدل نهایی ایجاد میکند.
پیگیری اخبار هوش مصنوعی و فناوری های وابسته به آن
ایرانتک یکی از شرکتهای فعال در حوزه هوش مصنوعی و فناوریهای وابسته به آن است. شما عزیزان برای کسب اطلاعات بیشتر در این زمینه کافی است به سایت رسمی ایرانتک مراجعه کنید.
سخن آخر
الگوریتم درخت تصمیم به ما کمک میکند تا بتوانیم با استفاده از دادههای موجود و با روشی ساده و قابل فهم، مدلهای پیشبینی ایجاد کنیم که میتوانند در تصمیمگیریهای تجاری و تحلیلهای داده مورد استفاده قرار گیرند. در این مقاله با مثال ساده نشان دادیم که چگونه درخت تصمیم میتواند به سؤالات پیچیده با استفاده از یک روش ساده و شفاف پاسخ دهد. امیدواریم در این مقاله توانسته باشیم به این سوال که الگوریتم درخت تصمیم چیست و چه کاربردی دارد، به طور کامل پاسخ داده باشیم. شما عزیزان میتوانید سوالات خود را در رابطه با این فناوری با کارشناسان ما در میان بگذارید.
سوالات متداول
1. درخت تصمیم چیست و چگونه کار میکند؟
درخت تصمیم یک مدل پیش بینی کننده است که از یک ساختار درختی برای تقسیم دادهها به دستههای مختلف استفاده میکند. هر گره داخلی یک سؤال یا شرط مربوط به ویژگیهای دادهها را نشان میدهد و گرههای برگ نتیجه نهایی یا پیشبینی را نشان میدهند.
2. مزایای درخت تصمیم چیست؟
سادگی و تفسیر پذیری: به راحتی قابل فهم و تفسیر است.
عدم نیاز به آماده سازی پیچیده دادهها: نیاز به نرمال سازی یا استاندارد سازی دادهها ندارد.
توانایی کار با دادههای گمشده: میتواند به خوبی با دادههای گمشده کار کند.
3. چگونه میتوان از بیشبرازش (Overfitting) در درخت تصمیم جلوگیری کرد؟
با استفاده از تکنیکهایی مانند هرس کردن (Pruning)، محدود کردن عمق درخت، و استفاده از الگوریتمهای ترکیبی مانند جنگل تصادفی (Random Forest) میتوان از بیشبرازش جلوگیری کرد.