










مقدمه
بیش برازش (Overfitting) یک مفهوم مهم در مدلهای یادگیری ماشین است که وقتی مدل به دادههای آموزشی خود به طور زیادی عادت کرده و جزئیات کوچک آنها را حفظ میکند، اتفاق میافتد. این امر میتواند منجر به عملکرد نامناسب مدل بر روی دادههای جدید (دادههایی که در آموزش شرکت نداشتهاند) شود، زیرا مدل قدرتمندی دارد که توانایی یادگیری نویز و جزئیات بیاهمیت را دارد که ممکن است بر روی دادههای جدید عملکرد را تخریب کند. هدف اصلی از پیشگیری از بیش برازش، ساخت مدلهایی است که قادر به عمومسازی الگوها از دادههای آموزشی به دادههای جدید باشند، به جای اینکه به طور خاص و دقیق بر دادههای آموزشی متمرکز شوند. استفاده از روشهایی مانند اعتبارسنجی متقابل (Cross-validation)، استفاده از مدلهای سادهتر، استفاده از تکنیکهای مانند کاهش اندازه (Regularization) و استفاده از دادههای بیشتر به عنوان راهکارهایی برای پیشگیری از بیش برازش مدلهای یادگیری ماشین مطرح هستند. در این مقاله قصد داریم به بررسی بیشتری در رابطه با اینکه بیش برازش چیست و راههای جلوگیری از ایجاد آن کدام است، بپردازیم. پس برای کسب اطلاعات بیشتر در این زمینه با ما همراه شوید.
فهرست
بیش برازش چیست و راههای جلوگیری از ایجاد آن کدام است؟
رابطه ی بیش برازش و هوش مصنوعی چیست؟
دلایل به وجود آمدن بیش برازش چیست؟
تفاوت بیش برازش (Overfitting)، کم برازش (Underfitting) و برازش مناسب چیست؟
پیگیری اخبار فناوری و اطلاعات در زمینه هوش مصنوعی
بیش برازش چیست و راههای جلوگیری از ایجاد آن کدام است؟
بیش برازش در مدلهای یادگیری ماشینی به وضعیتی اطلاق میشود که مدل به طور غیرمناسبی به دادههای آموزش خود عادت کرده و در نتیجه عملکرد خوبی در دادههای آموزش دارد. اما وقتی با دادههای جدید یا تستی مواجه میشود، عملکرد آن ناپایدار و ضعیف میشود. این موضوع معمولا به دلیل پیچیدگی زیاد مدل نسبت به دادههای آموزشی و یا تعداد پارامترهای زیاد مدل اتفاق میافتد.
برای جلوگیری از بیش برازش، میتوان اقدامات زیر را انجام داد:
- استفاده از دادههای بیشتر: یکی از راههای اصلی جلوگیری از بیش برازش افزایش حجم دادههای آموزشی است. با افزایش تعداد نمونهها، احتمال این که مدل به اطلاعات جزئی و تصادفی دادهها عادت کند کاهش مییابد.
- استفاده از روشهای ارزیابی مناسب: برای ارزیابی مدل بهتر، از روشهایی مانند اعتبار سنجی متقاطع (Cross-validation) استفاده کنید. برای اینکه اطمینان حاصل شود که مدل عملکرد خوبی روی دادههای تست نیز خواهد داشت و بیش برازش رخ ندهد.
- ساده سازی مدل: انتخاب مدلهای کمتر پیچیدهتر، که کمترین تعداد پارامترها را دارند، میتواند کمک کند تا بیش برازش کاهش یابد. مدلهایی مانند رگرسیون خطی به جای رگرسیون چند جملهای یا شبکههای عصبی سادهتر به جای شبکههای عمیق.
- استفاده از تکنیکهای Regularization: اضافه کردن جریمه به توابع هزینه مانند جریمه L1 یا L2 (Regularization) میتواند کمک کند تا مدل کمتر به پارامترهای دادههای آموزشی عادت کند. در نتیجه برازش بهتری به همراه دارد.
- ردیابی و تنظیم پارامترها: در طول آموزش، نظارت بر عملکرد مدل بر روی دادههای آموزش و اعتبارسنجی و تنظیم پارامترها بر اساس نتایج به دست آمده میتواند از بیش برازش جلوگیری کند.
با انجام این اقدامات، میتوانید از بیش برازش در مدلهای یادگیری ماشینی جلوگیری کرده و عملکرد بهتری بر روی دادههای جدید به دست آورید.
رابطه ی بیش برازش و هوش مصنوعی چیست؟
بیش برازش در ارتباط با هوش مصنوعی به مفهوم پدیدهای اشاره دارد که در مدلهای یادگیری ماشینی و هوش مصنوعی رخ میدهد. در این پدیده، مدل به طور غیرمناسبی به دادههای آموزش خود عادت میکند و جزئیات و نویزهای موجود در دادههای آموزش را به عنوان الگو یاد میگیرد. به گونهای که عملکرد خوبی روی دادههای آموزش دارد، اما وقتی با دادههای جدید یا تستی مواجه میشود، عملکرد آن ناپایدار و ضعیف میشود.
ارتباط بیش برازش با هوش مصنوعی به این صورت است که در پیاده سازی الگوریتمها و مدلهای هوش مصنوعی، هدف اصلی این است که مدلها توانایی تعمیم پذیری (Generalization) را داشته باشند. به این معنی که نه تنها بر روی دادههای آموزش خوب عمل کنند بلکه بتوانند الگوها و قوانینی که از دادههای آموزش یاد گرفتهاند را بر روی دادههای جدید و ناآشنا هم به خوبی تعمیم دهند.
بیش برازش در اینجا مسئلهای مهم است زیرا اگر یک مدل بیش برازش داشته باشد، این به معنی ضعف توانایی تعمیمپذیری مدل است. در نتیجه، عملکرد آن در برابر دادههای جدید قابل پیشبینی نخواهد بود و عملا مدل از نظر کاربردی کم ارزش میشود.
دلایل به وجود آمدن بیش برازش چیست؟
بیش برازش یک پدیده در یادگیری ماشینی است که به طور اصطلاحی در آموزش مدلها رخ میدهد و دلایل مختلفی میتواند به وجود آن منجر شود. برخی از دلایل اصلی به وجود آمدن بیش برازش عبارتند از:
پیچیدگی مدل
استفاده از مدلهای بسیار پیچیده و با تعداد پارامترهای زیاد میتواند منجر به بیش برازش شود. این امر باعث میشود که مدل به دادههای آموزشی به طور دقیق عادت کند. همچنین میتواند الگوها و نویزهای کوچک در دادههای آموزش را نیز تشخیص دهد که این الگوها برای دادههای جدید نماینده خوبی نیستند.
تعداد کم دادههای آموزش
وجود تعداد کم دادههای آموزشی میتواند باعث شود که مدل نتواند یاد بگیرد که چگونه دادههای جدید را به درستی تعمیم دهد. سپس به جای آن به دادههای آموزشی خود بیش برازش کند.
نویز و انحرافات در دادهها
وجود نویز، خطاها و انحرافات در دادهها ممکن است باعث شود که مدل به شکل ناخواسته به این نویزها هم عادت کند که به بیش برازش منجر میشود.
عدم تعمیمپذیری الگوریتمها
برخی الگوریتمها یا مدلهای خاص ممکن است از نظر طراحی، قدرت تعمیم پذیری کمی داشته باشند و بیشتر به دادههای آموزشی تعلق داشته باشند.
نیاز به تنظیم پارامترها
اگر پارامترهای مدل به درستی تنظیم نشوند، ممکن است مدل به دادههای آموزشی خود بیش برازش کند و برای دادههای جدید عملکرد ضعیفی داشته باشد.
تفاوت بین دادههای آموزشی و تستی
اگر دادههای آموزشی و تستی به گونهای باشند که ارتباط زیادی با یکدیگر نداشته یا شرایط متفاوتی داشته باشند، ممکن است مدل به دادههای آموزشی خود بیش برازش کند. در نتیجه برای دادههای جدید نتواند عملکرد مناسبی داشته باشد.

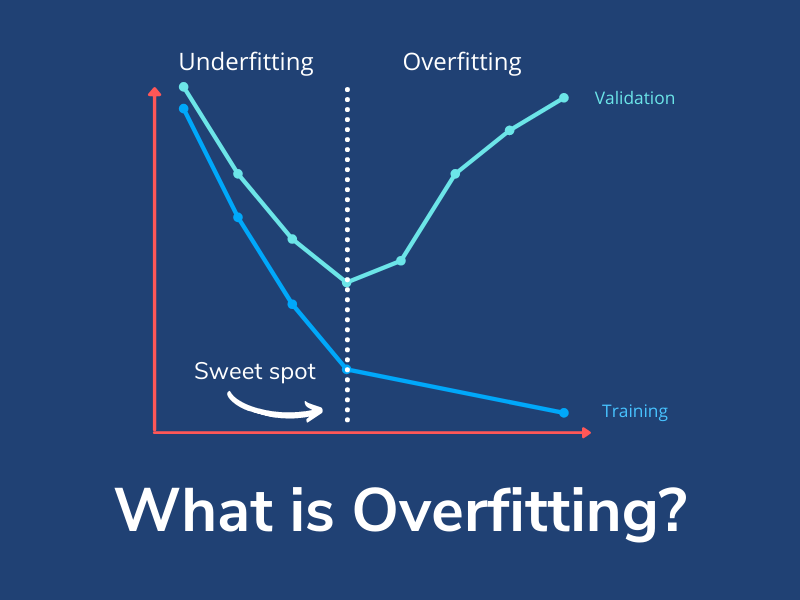
تفاوت بیش برازش (Overfitting)، کم برازش (Underfitting) و برازش مناسب چیست؟
بیش برازش (Overfitting)، کم برازش (Underfitting) و برازش مناسب (Good fitting) سه حالت مختلف در آموزش مدلهای یادگیری ماشینی هستند که هرکدام ویژگیها و علائم تشخیصی خاص خود را دارند:
بیش برازش (Overfitting)
در این حالت، مدل به طور غیرمناسبی به دادههای آموزشی عادت کرده و الگوها و جزئیات کوچک آنها را یاد میگیرد تا حدی که ممکن است این الگوها تصادفی و نویزی هم باشند.
- مشخصهها: عملکرد خوبی روی دادههای آموزشی دارد، اما عملکرد ناپایدار و ضعیفی روی دادههای جدید یا تستی ارائه میدهد.
- علل: پیچیدگی زیاد مدل، تعداد زیاد پارامترها، تعداد کم دادههای آموزشی، وجود نویز و انحرافات زیاد در دادهها از جمله دلایل این پدیده هستند.
کم برازش (Underfitting)
در این حالت، مدل خیلی ساده یا ضعیف است و نمیتواند به درستی الگوهای موجود در دادههای آموزشی را یاد بگیرد.
- مشخصهها: عملکرد ضعیف یا متوسط هم در دادههای آموزشی و هم در دادههای جدید. معمولاً خطای آموزشی و خطای تستی هر دو بالا هستند.
- علل: استفاده از مدلهای بسیار ساده، تعداد کم پارامترها، یا اینکه مدل توانایی کافی برای یادگیری الگوهای پیچیدهتر در دادهها را نداشته باشد.
برازش مناسب (Good fitting)
در این حالت، مدل به خوبی توانایی تعمیمپذیری دارد و الگوهای مهم در دادههای آموزشی را به درستی یاد میگیرد.
- مشخصهها: عملکرد خوب یا مناسب در دادههای آموزشی و همچنین عملکرد مقبولی روی دادههای جدید یا تستی.
- علل: استفاده از مدلی که پیچیدگی مناسبی داشته باشد، استفاده از تعداد مناسب دادههای آموزشی، استفاده از روشهای ارزیابی مناسب مانند اعتبارسنجی، و تنظیم مناسب پارامترهای مدل.
به طور خلاصه، هدف در آموزش مدلهای یادگیری ماشینی این است که به برازش مناسب برسیم، که به معنای یادگیری الگوهای مفید و کلیدی از دادههای آموزشی باشد و بتواند این الگوها را برای دادههای جدید به خوبی تعمیم دهد، در حالی که از بیش برازش و کم برازش پرهیز کنیم که موجب عملکرد نامناسب مدل در مواجهه با دادههای جدید میشود.

پیگیری اخبار فناوری و اطلاعات در زمینه هوش مصنوعی
ایرانتک یکی از شرکتهای فعال در زمینه هوش مصنوعی و فناوری های مرتبط با آن است. شما عزیزان با مراجعه به سایت این شرکت میتوانید در قسمت اخبار و مقالات اطلاعات خود را در زمینه فناوری های نوین افزایش دهید.
کلام پایانی
بیش برازش نتیجهای از عدم تعمیم پذیری و کلیتی بودن یادگیری مدل است. این فناوری میتواند با استفاده از روشهایی مانند استفاده از دادههای بیشتر، ساده سازی مدل، استفاده از روشهای Regularization و نظارت مداوم بر عملکرد مدل، کاهش داده شود. مقابله با بیش برازش و جلوگیری از آن از جمله چالشهای مهم در طراحی و پیاده سازی مدلهای هوش مصنوعی است تا این مدلها بتوانند با دقت و قدرت به تصمیمگیری و پیشبینی در شرایط واقعی پرداخته و به عنوان یک ابزار مفید و قابل اعتماد در مسائل مختلف مورد استفاده قرار گیرند. در این مقاله به طور کامل به بررسی اینکه بیش برازش چیست و راههای جلوگیری از ایجاد آن کدام است، پرداختیم. شما عزیزان میتوانید سوالات خود را در این زمینه با ما در میان بگذارید.
سوالات متداول
1. بیش برازش چیست؟
بیش برازش یا Overfitting به وضعیتی اطلاق میشود که مدل یادگیری ماشینی به طور غیرمناسبی به دادههای آموزشی عادت کرده و الگوهای نویزی و جزئیات غیرضروری را نیز به عنوان الگو یاد میگیرد، که به نتیجه مناسبی برای دادههای جدید نمیرسد.
2. چه علائمی برای بیش برازش وجود دارد؟
علائم بیش برازش شامل افزایش خطا در دادههای تست نسبت به دادههای آموزش، تغییرات بزرگ و نامنظم در پارامترهای مدل، و تفاوت زیاد بین عملکرد مدل در دادههای آموزش و تست میشود.
3. چطور میتوان از بیش برازش جلوگیری کرد؟
برای جلوگیری از بیش برازش، میتوان از روشهایی مانند استفاده از دادههای بیشتر برای آموزش، سادهسازی مدل، استفاده از روشهای Regularization مانند L1 و L2، و استفاده از اعتبارسنجی مناسب برای ارزیابی مدل استفاده کرد.