











مقدمه
مدل پیشبینی کننده یک ابزار ریاضی یا آماری است که از دادههای گذشته برای پیشبینی نتایج آینده استفاده میکند. این مدلها با تجزیه و تحلیل الگوها و روابط موجود در دادهها، توانایی پیشبینی وقایع یا نتایج را دارند. کاربردهای آنها شامل پیشبینی فروش، تشخیص بیماریها، ارزیابی ریسکهای مالی، شناسایی مشتریانی که احتمال ترک دارند و غیره میشود. به عنوان مثال، یک مدل پیشبینی کننده میتواند به یک شرکت کمک کند تا مشتریانی که ممکن است اشتراک خود را قطع کنند شناسایی کند و اقداماتی برای حفظ آنها انجام دهد. در ادامه مقاله به بررسی کاملتری در رابطه با اینکه مدل پیشبینی کننده (Predictive model) چیست و چه کاربردهایی دارد، میپردازیم. پس برای کسب اطلاعات بیشتر با ما همراه شوید.
فهرست
مدل پیشبینی کننده (Predictive model) چیست؟
اجزای اصلی مدلهای پیشبینی کننده چیست؟
انواع مدلهای پیشبینی کننده چیست؟
مراحل ساخت مدل پیشبینی کننده چیست؟
پیگیری اخبار فناوری و هوش مصنوعی
مدل پیشبینی کننده (Predictive model) چیست؟
مدل پیشبینی کننده (Predictive model) یک ابزار یا الگوریتم است که برای پیشبینی نتایج و اتفاقات آینده بر اساس دادههای تاریخی و الگوهای موجود در این دادهها استفاده میشود. این مدلها در زمینههای مختلفی از جمله تجارت، پزشکی، علوم اجتماعی، مهندسی و غیره کاربرد دارند. مدلهای پیشبینی کننده معمولاً با استفاده از روشهای آماری، یادگیری ماشین یا ترکیبی از این دو ساخته میشوند. در ادامه با یک مثال به توضیح بیشتر این مدل میپردازیم.
پیشبینی ترک مشتریان (Customer Churn Prediction)
شرکتی که خدمات اشتراکی ارائه میدهد، مانند یک ارائه دهنده خدمات اینترنتی یا یک سرویس پخش آنلاین، با مسئله ترک مشتریان مواجه است. ترک مشتریان به معنای قطع اشتراک توسط مشتریان است که میتواند تأثیر منفی بر درآمد و رشد شرکت داشته باشد. هدف این شرکت شناسایی مشتریانی است که احتمال ترک بالایی دارند تا بتواند اقدامات پیشگیرانهای برای حفظ آنها انجام دهد. مراحل ساخت مدل برای این مثال به شرح زیر است:
جمعآوری دادهها
دادههای مربوط به مشتریان فعلی و قبلی جمع آوری میشوند. این دادهها شامل ویژگیهایی مانند مدت زمان اشتراک، میزان استفاده از خدمات، تعداد تماسهای با پشتیبانی، رضایت مشتریان از خدمات و اطلاعات دموگرافیک است.
پاک سازی و آماده سازی دادهها
دادههای جمع آوری شده بررسی و پاک سازی میشوند تا مقادیر گمشده یا اشتباه تصحیح شوند. ویژگیهای مهم که بر ترک مشتریان تأثیر دارند شناسایی و استخراج میشوند.
آموزش مدل
دادهها به مجموعههای آموزشی و آزمایشی تقسیم میشوند. یک الگوریتم پیشبینی کننده مانند جنگل تصادفی (Random Forest) یا شبکههای عصبی (Neural Networks) انتخاب و مدل با استفاده از دادههای آموزشی، آموزش داده میشود.
ارزیابی مدل
مدل با استفاده از دادههای آزمایشی ارزیابی میشود تا دقت و کارایی آن سنجیده شود. معیارهایی مانند دقت (Accuracy)، حساسیت (Recall) و دقت مثبت (Precision) برای ارزیابی عملکرد مدل استفاده میشوند.
پیاده سازی و استفاده از مدل
مدل پیشبینی کننده در سیستمهای عملیاتی شرکت پیاده سازی میشود تا مشتریانی که احتمال ترک بالایی دارند شناسایی شوند. این اطلاعات به تیم بازاریابی و پشتیبانی ارسال میشود تا با ارائه پیشنهادات ویژه یا تخفیفات، تلاش کنند این مشتریان را حفظ کنند.

اجزای اصلی مدلهای پیشبینی کننده چیست؟
مدلهای پیشبینی کننده شامل اجزای مختلفی هستند که هر کدام نقش مهمی در فرآیند پیشبینی و دقت نتایج دارند. اجزای اصلی مدلهای پیشبینی کننده به شرح زیر هستند:
دادهها (Data)
دادهها پایه و اساس هر مدل پیشبینی کننده هستند. این دادهها میتوانند شامل اطلاعات تاریخی، ویژگیهای مختلف و نتایج مورد انتظار باشند. انواع دادهها به شرح زیر است.
- آموزشی (Training Data): دادههایی که برای آموزش مدل استفاده میشوند.
- اعتبارسنجی (Validation Data): دادههایی که برای تنظیم و بهینه سازی مدل استفاده میشوند.
- آزمایشی (Test Data): دادههایی که برای ارزیابی نهایی عملکرد مدل استفاده میشوند.
ویژگیها (Features)
ویژگیها متغیرهای ورودی هستند که مدل بر اساس آنها پیشبینی میکند. انتخاب و استخراج ویژگیهای مناسب و موثر (Feature Engineering) یکی از مهمترین مراحل در ساخت مدلهای پیشبینی کننده است.
برچسبها (Labels)
برچسبها خروجیهای مورد انتظار یا نتایج واقعی هستند که مدل باید پیشبینی کند. در مدلهای رگرسیونی، برچسبها مقادیر عددی و در مدلهای دسته بندی، برچسبها دستههای مختلف هستند.
الگوریتم پیشبینی (Predictive Algorithm)
الگوریتم پیشبینی روش یا فرمول ریاضی است که مدل برای یادگیری از دادهها و انجام پیشبینیها از آن استفاده میکند. انواع مختلفی از الگوریتمها وجود دارند که برای کاربردهای مختلف مناسب هستند.
مدل (Model)
مدل ترکیبی از دادهها، ویژگیها، و الگوریتم پیشبینی است که پس از آموزش، آماده استفاده برای پیشبینی نتایج جدید میباشد.
تابع هزینه (Cost Function) یا تابع زیان (Loss Function)
تابع هزینه معیاری است که میزان خطای مدل را اندازهگیری میکند. مدلها با کمینه سازی این تابع آموزش داده میشوند تا دقت پیشبینیها افزایش یابد.
روشهای بهینه سازی (Optimization Methods)
روشهای بهینه سازی برای کمینه سازی تابع هزینه و بهبود عملکرد مدل استفاده میشوند. نمونههایی از این روشها شامل گرادیان کاهشی (Gradient Descent)، بهینه سازی استوکستیک (Stochastic Optimization) و غیره هستند.
معیارهای ارزیابی (Evaluation Metrics)
معیارهای ارزیابی برای سنجش عملکرد مدل استفاده میشوند. این معیارها بسته به نوع مسئله متفاوت هستند، مانند دقت (Accuracy)، دقت مثبت (Precision)، حساسیت (Recall)، و میانگین مربعات خطا (Mean Squared Error).
اعتبارسنجی مدل (Model Validation)
اعتبارسنجی شامل تکنیکهایی مانند Cross-Validation است که برای ارزیابی مدل و جلوگیری از بیش برازش (Overfitting) استفاده میشوند.
پیاده سازی و استقرار مدل (Model Deployment)
پس از ساخت و ارزیابی مدل، مرحله پیاده سازی و استقرار مدل میآید که مدل آماده استفاده در محیطهای واقعی میشود.
بازخورد و بهروزرسانی مدل (Model Feedback and Updating)
مدلهای پیشبینی کننده به بازخورد و بهروزرسانیهای دورهای نیاز دارند تا با دادههای جدید و شرایط متغیر هماهنگ شوند و عملکرد بهینه خود را حفظ کنند.
این اجزا با هم ترکیب شده و مدل پیشبینی کنندهای را تشکیل میدهند که میتواند نتایج آینده را با دقت مناسبی پیشبینی کند.

انواع مدلهای پیشبینی کننده چیست؟
مدلهای پیشبینی کننده انواع مختلفی دارند که هر کدام برای حل مسائل خاصی طراحی شدهاند. این مدلها میتوانند به سه دسته اصلی تقسیم شوند: مدلهای رگرسیون (Regression Models)، مدلهای دسته بندی (Classification Models) و مدلهای سری زمانی (Time Series Models). در ادامه، هر کدام از این دستهها را به تفصیل توضیح میدهیم.
مدلهای رگرسیون (Regression Models)
مدلهای رگرسیون برای پیشبینی مقادیر عددی مستمر استفاده میشوند. در این مدلها، خروجی یک متغیر پیوسته است.
رگرسیون خطی (Linear Regression): سادهترین و رایجترین نوع مدل رگرسیون نوع خطی است. این مدل سعی میکند تا رابطه خطی بین متغیر وابسته (خروجی) و یک یا چند متغیر مستقل (ورودی) پیدا کند. کاربردهای این مدل شامل پیشبینی قیمت خانه، پیشبینی فروش و تحلیل دادههای مالی است.
رگرسیون چندگانه (Multiple Regression): این مدل، نسخهای از رگرسیون خطی بوده که شامل چندین متغیر مستقل است. کاربردهای آن شامل تحلیل تاثیر عوامل متعدد بر فروش یک محصول میشود.
رگرسیون لجستیک (Logistic Regression): از رگرسیون لجستیک برای پیشبینی احتمال وقوع یک رویداد باینری استفاده میشود. خروجی این مدلها معمولاً بین 0 و 1 است. کاربردهای این رگرسیون شامل تشخیص بیماری، پیشبینی مشتریانی که احتمال دارد یک محصول را خریداری کنند، میشود.
رگرسیون ریج (Ridge Regression) و لاسو (Lasso Regression): انواع رگرسیون خطی که از تکنیکهای منظم سازی (Regularization) برای جلوگیری از بیشبرازش استفاده میکنند. کاربردهای آن شامل حل مسائل رگرسیون با تعداد زیادی ویژگی است.
مدلهای دسته بندی (Classification Models)
مدلهای دسته بندی برای طبقهبندی دادهها به دستههای مختلف استفاده میشوند. خروجی این مدلها معمولاً دسته یا کلاس است.
ماشین بردار پشتیبان (Support Vector Machine – SVM): الگوریتمی که به دنبال یافتن بهترین مرز برای جدا کردن دادهها به دستههای مختلف است. تشخیص چهره، دستهبندی ایمیلها به اسپم و غیر اسپم از کاربردهای این مدل است.
درخت تصمیم (Decision Tree): مدل دستهبندی که از ساختار درختی برای تصمیمگیری استفاده میکند.
کاربردهای این الگوریتم تحلیل ریسک و ارزیابی اعتبار مشتری است.
جنگل تصادفی (Random Forest): الگوریتمی که از ترکیب چندین درخت تصمیم برای بهبود دقت و کاهش بیشبرازش استفاده میکند. پیشبینی بیماریها و دسته بندی تصاویر جزء کاربردهای جنگل تصادفی است.
شبکههای عصبی مصنوعی (Artificial Neural Networks): مدلهای محاسباتی الهام گرفته از ساختار مغز انسان که برای مسائل پیچیده دستهبندی مناسب هستند. کاربردهای تشخیص گفتار، ترجمه ماشینی و دستهبندی تصاویر است.
مدلهای بیز ساده (Naive Bayes): مدل دستهبندی که بر پایه تئوری بیز و فرض استقلال ویژگیها استوار است.
کاربردهای این مدل فیلتر اسپم و تحلیل احساسات است.
مدلهای سری زمانی (Time Series Models)
مدلهای سری زمانی برای پیشبینی مقادیر بر اساس دادههای زمانی استفاده میشوند. این مدلها به تحلیل دادهها در طول زمان میپردازند.
مدلهای میانگین متحرک خودبازگشتی (ARIMA – Autoregressive Integrated Moving Average): مدلهای سری زمانی که ترکیبی از میانگین متحرک و مدلهای خودبازگشتی هستند. پیشبینی فروش ماهانه، پیشبینی تقاضای انرژی از کاربردهای این مدل است.
مدلهای هموارسازی نمایی (Exponential Smoothing): مدلهایی که به دادههای جدید وزن بیشتری میدهند و برای پیشبینیهای کوتاه مدت مناسب هستند. کاربردهای این مدل شامل پیشبینی فروش در فروشگاههای خردهفروشی میشود.
شبکههای عصبی بازگشتی (Recurrent Neural Networks – RNN): نوعی از شبکههای عصبی که برای پردازش دادههای دنبالهدار و سری زمانی مناسب هستند. پیشبینی قیمت سهام و تحلیل رفتار مشتری از کاربردهای این مدل است.
مدلهای ترکیبی (Ensemble Models)
مدلهای ترکیبی از ترکیب چندین مدل برای بهبود دقت و عملکرد استفاده میکنند.
بوستینگ (Boosting): تکنیکی که مدلهای ضعیف را به ترتیب آموزش داده و ترکیب میکند تا یک مدل قویتر بسازد. پیشبینیهای مالی و شناسایی تقلب از کاربردهای مدل است.
بگینگ (Bagging): تکنیکی که مدلهای متعددی را به طور مستقل آموزش داده و نتایج آنها را ترکیب میکند. دسته بندی و رگرسیون از کاربردهای مدل های ترکیبی است.
مدلهای خوشه بندی (Clustering Models)
مدلهای خوشه بندی برای گروهبندی دادهها به خوشههای مشابه بدون نیاز به برچسبهای مشخص استفاده میشوند.
الگوریتم K-میانگین (K-Means): الگوریتمی که دادهها را به K خوشه تقسیم میکند. بخش بندی بازار و تحلیل رفتار مشتری از کاربردهای مدل خوشه بندی است.
خوشه بندی سلسلهمراتبی (Hierarchical Clustering): روش خوشه بندی که دادهها را به صورت سلسله مراتبی گروه بندی میکند. تحلیل ژنتیکی و تقسیم بندی تصویر از کاربردهای این مدل است.
بیشتر بدانید: تحلیل پیشبینی کننده چیست؟

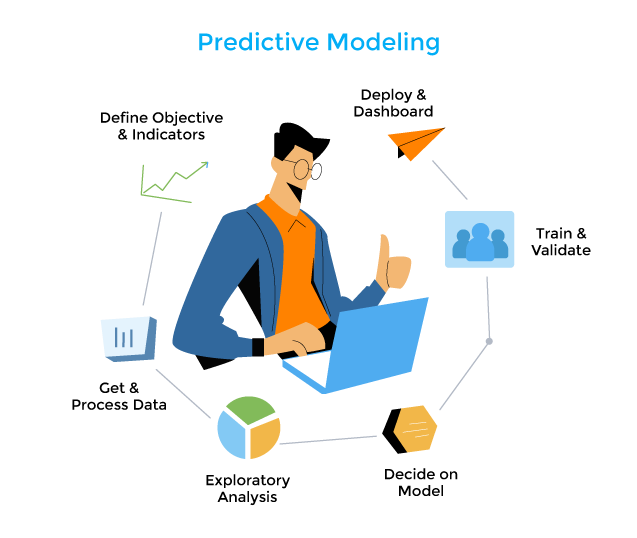
مراحل ساخت مدل پیشبینی کننده چیست؟
ساخت یک مدل پیشبینی کننده فرآیندی سیستماتیک و چند مرحلهای است که شامل جمع آوری و آماده سازی دادهها، انتخاب الگوریتم مناسب، آموزش مدل، ارزیابی و بهینه سازی آن میشود. در ادامه، مراحل ساخت یک مدل پیشبینی کننده را به طور کامل توضیح میدهیم:
تعریف مسئله (Problem Definition)
قبل از هر چیز، باید مسئلهای که قصد حل آن را دارید به دقت تعریف کنید. این شامل مشخص کردن متغیر وابسته (خروجی) و متغیرهای مستقل (ویژگیها) است.
جمع آوری دادهها (Data Collection)
جمع آوری دادههای مرتبط و معتبر اولین گام عملی در ساخت مدل پیشبینی کننده است. این دادهها میتوانند از منابع مختلفی مانند دیتابیسها، APIها، فایلهای CSV و غیره جمع آوری شوند.
پاک سازی دادهها (Data Cleaning)
دادههای جمع آوری شده معمولاً شامل نویز، مقادیر گمشده، دادههای تکراری و اشتباهات هستند. پاک سازی دادهها شامل شناسایی و تصحیح این مشکلات میشود.
اکتشاف و تحلیل دادهها (Data Exploration and Analysis)
در این مرحله، دادهها بررسی و تحلیل میشوند تا الگوها و روابط بین متغیرها شناسایی شوند. ابزارهای آماری و بصری سازی دادهها مانند نمودارها و جداول محوری (Pivot Tables) مفید هستند.
انتخاب ویژگیها (Feature Selection)
شناسایی ویژگیهای مهم و موثر که بیشترین تاثیر را بر پیش بینی خروجی دارند. این مرحله شامل استفاده از تکنیکهای مختلف مانند تحلیل واریانس (ANOVA)، همبستگی و تستهای آماری است.
مهندسی ویژگیها (Feature Engineering)
ساخت ویژگیهای جدید از ویژگیهای موجود برای بهبود عملکرد مدل. این شامل تبدیل دادهها، نرمال سازی، استانداردسازی و غیره میشود.
تقسیم دادهها (Data Splitting)
تقسیم دادهها به سه مجموعه: دادههای آموزشی (Training Set)، دادههای اعتبارسنجی (Validation Set) و دادههای آزمایشی (Test Set). این تقسیم بندی معمولاً به صورت 70-20-10 یا 80-20 انجام میشود.
انتخاب الگوریتم (Algorithm Selection)
انتخاب الگوریتم مناسب برای مسئله مورد نظر. این انتخاب بر اساس نوع مسئله (رگرسیون، دستهبندی، سری زمانی)، پیچیدگی دادهها و نیازهای محاسباتی انجام میشود.
آموزش مدل (Model Training)
آموزش مدل با استفاده از دادههای آموزشی. در این مرحله، مدل الگوها و روابط موجود در دادهها را یاد میگیرد.
اعتبارسنجی مدل (Model Validation)
استفاده از دادههای اعتبارسنجی برای ارزیابی عملکرد مدل و تنظیم هایپرپارامترها (Hyperparameters). تکنیکهایی مانند Cross-Validation در این مرحله استفاده میشوند.
ارزیابی مدل (Model Evaluation)
ارزیابی نهایی مدل با استفاده از دادههای آزمایشی. معیارهای ارزیابی شامل دقت (Accuracy)، حساسیت (Recall)، دقت مثبت (Precision)، میانگین مربعات خطا (Mean Squared Error) و غیره هستند.
بهینهسازی مدل (Model Optimization)
بهبود مدل بر اساس نتایج ارزیابی و انجام تنظیمات لازم. این مرحله شامل تنظیم هایپرپارامترها، بهبود ویژگیها و انتخاب الگوریتمهای بهینهتر است.
پیاده سازی مدل (Model Deployment)
پیاده سازی مدل در محیط عملیاتی. این مرحله شامل ایجاد رابطهای کاربری، APIها و سیستمهای خودکار برای استفاده از مدل در دنیای واقعی است.
پایش و بهروزرسانی مدل (Model Monitoring and Updating)
پایش عملکرد مدل به طور مداوم و بهروزرسانی آن بر اساس دادههای جدید و تغییرات محیطی. این مرحله شامل بازآموزی مدل، افزودن دادههای جدید و بهبود مستمر است.
مستند سازی (Documentation)
مستند سازی کل فرآیند ساخت مدل، شامل روشها، الگوریتمها، تنظیمات و نتایج به دست آمده. این مستندات برای بازتولید، ارزیابی و بهبود مدل در آینده مفید هستند.
این مراحل به صورت تکراری و چرخهای اجرا میشوند تا مدل بهینه و قابل اعتمادی ساخته شود که قادر به پیشبینی دقیق و کارآمد نتایج باشد.
پیگیری اخبار فناوری و هوش مصنوعی
ایرانتک یکی از شرکتهای معتبر و باسابقه در انتشار اخبار و مقالات در رابطه با هوش مصنوعی و فناوریهای وابسته به آن است. شما عزیزان کافی است با مراجعه به سایت در قسمت اخبار و مقالات اطلاعات خود را در این زمینه افزایش دهید.
سخن آخر
مدل پیشبینی کننده (Predictive Model) سیستمی است که با استفاده از دادههای موجود و تحلیل الگوهای گذشته، تلاش میکند تا نتایج و رخدادهای آینده را پیشبینی کند. این مدلها در زمینههای مختلفی مانند بازاریابی، مالی، بهداشت و حمل و نقل به کار میروند تا تصمیمگیریها را بهبود بخشند. به طور مثال، یک شرکت میتواند با استفاده از مدل پیشبینی کننده، مشتریانی را که احتمال دارد اشتراک خود را لغو کنند شناسایی کند و با ارائه پیشنهادات خاص از این اتفاق جلوگیری کند. در این مقاله به طور کامل به بررسی اینکه مدل پیشبینی کننده چیست و چه کاربردهایی دارد، پرداختیم. شما عزیزان میتوانید سوالات خود را در این زمینه با ما در میان بگذارید.
سوالات متداول
1. مدل پیشبینی کننده چیست؟
مدل پیشبینی کننده یک ابزار آماری یا یادگیری ماشین است که از دادههای گذشته برای پیشبینی نتایج آینده استفاده میکند.
2. چگونه مدل پیشبینی کننده کار میکند؟
این مدل با تحلیل الگوها و روابط موجود در دادههای تاریخی، الگویی ایجاد میکند که به پیشبینی رخدادها یا نتایج آینده کمک میکند.
3. کاربردهای مدل پیشبینی کننده چیست؟
مدلهای پیشبینی کننده در حوزههایی مانند بازاریابی، مالی، بهداشت و حمل و نقل برای پیشبینی فروش، تشخیص بیماریها، ارزیابی ریسک و بهینهسازی فرآیندها به کار میروند.