











مقدمه
الگوریتم نزدیکترین همسایه یکی از سادهترین الگوریتمهای یادگیری ماشین است که برای مسائل طبقهبندی و پیشبینی استفاده میشود. هدف اصلی در ساخت این الگوریتم، تشخیص الگوها و روابط میان دادهها بدون نیاز به آموزش پیشین یا ساخت مدل پیچیده است. این الگوریتم به علت سادگی پیاده سازی و قابلیت اعمال در مسائل مختلف، از جمله زندگی روزمره و علوم مختلف از جمله پزشکی، تجارت، و فناوری اطلاعات استفاده میشود تا الگوها و روابط پنهان در دادهها را شناسایی و بهبود کیفیت تصمیمگیریها و پیشبینیها کمک کند. در ادامه به بررسی بیشتری در رابطه با اینکه الگوریتمهای نزدیکترین همسایه (KNN) چیست و چه کاربردی دارد، میپردازیم. پس برای کسب اطلاعات بیشتر با ما همراه شوید.
فهرست
الگوریتمهای نزدیکترین همسایه (KNN) چیست؟
کاربردهای الگوریتمهای نزدیکترین همسایه
مزایا و چالشهای الگوریتمهای نزدیکترین همسایه (KNN) چیست؟
نقش الگوریتمهای نزدیکترین همسایه (KNN) را در زندگی روزمره
پیگیری اخبار فناوری و اطلاعات
الگوریتمهای نزدیکترین همسایه (KNN) چیست؟
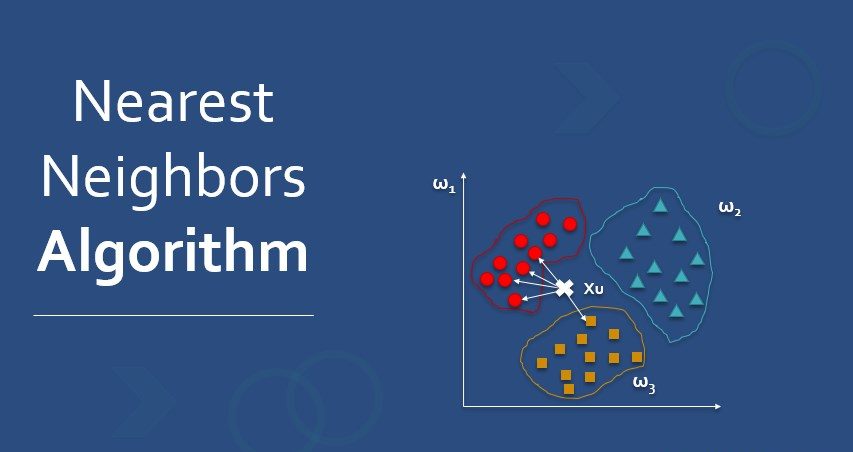
الگوریتم نزدیکترین همسایه (K-Nearest Neighbors یا KNN) یکی از سادهترین و محبوبترین الگوریتمهای یادگیری ماشین است که برای مسائل طبقهبندی و رگرسیون به کار میرود. این الگوریتم بر اساس اصل تشابه عمل میکند؛ یعنی نمونههای مشابه با یکدیگر به احتمال زیاد دارای ویژگیهای مشابهی هستند. در KNN، فرض بر این است که اشیایی که در یک فضای ویژگی نزدیک به هم هستند، دارای کلاسهای مشابهی نیز هستند.
در فرآیند طبقهبندی با استفاده از KNN، ابتدا تعداد K که تعیینکننده تعداد نزدیکترین همسایهها است، انتخاب میشود. سپس برای هر نمونه جدید، فاصله آن از تمامی نمونههای موجود در مجموعه داده محاسبه میشود. فاصلهها معمولاً با استفاده از متریکهایی مانند فاصله اقلیدسی محاسبه میشوند. بعد از محاسبه فاصلهها، K نمونه با کمترین فاصله به عنوان همسایههای نزدیک انتخاب میشوند. کلاس نمونه جدید بر اساس اکثریت کلاسهای این K همسایه تعیین میشود. به عبارت دیگر، نمونه جدید به کلاسی تعلق میگیرد که بیشترین تعداد همسایههای نزدیک از آن کلاس باشند.
در مسائل رگرسیون، به جای طبقهبندی، مقدار خروجی به عنوان میانگین مقادیر K نزدیکترین همسایه محاسبه میشود. به این ترتیب، KNN میتواند در پیشبینی مقادیر پیوسته نیز مؤثر باشد. یکی از مزایای KNN این است که الگوریتم نیاز به هیچگونه یادگیری یا آموزش ندارد و تمام محاسبات در زمان پیشبینی انجام میشود، که این ویژگی باعث سادگی و انعطافپذیری آن میشود.
با این حال، KNN دارای معایبی نیز هست. از جمله این معایب میتوان به کندی و مصرف حافظه زیاد در مجموعه دادههای بزرگ اشاره کرد، زیرا برای هر نمونه جدید باید فاصلهها با تمامی نمونههای موجود محاسبه شود. همچنین، انتخاب مناسب K نقش مهمی در عملکرد الگوریتم دارد و اگر K بسیار کوچک یا بسیار بزرگ انتخاب شود، ممکن است نتایج نادرستی حاصل شود. به همین دلیل، معمولاً از روشهای اعتبارسنجی متقابل برای تعیین بهترین مقدار K استفاده میشود.

کاربردهای الگوریتمهای نزدیکترین همسایه
الگوریتمهای نزدیکترین همسایه (K-Nearest Neighbors یا KNN) در بسیاری از زمینهها و کاربردهای عملی استفاده میشوند. در زیر به برخی از مهمترین کاربردهای این الگوریتم اشاره میکنیم:
طبقهبندی تصاویر
KNN در طبقه بندی تصاویر و تشخیص اشیاء بسیار مؤثر است. با استفاده از ویژگیهای استخراج شده از تصاویر (مانند رنگ، بافت، و شکل)، میتوان تصاویر را به دستههای مختلفی طبقه بندی کرد. به عنوان مثال، تشخیص چهره، شناسایی دست نوشتهها و تفکیک انواع محصولات در تصاویر صنعتی از کاربردهای رایج است.
پردازش زبان طبیعی (NLP)
KNN در کاربردهای پردازش زبان طبیعی مانند طبقه بندی متن، تشخیص احساسات و فیلتر کردن ایمیلهای اسپم استفاده میشود. این الگوریتم با تحلیل ویژگیهای متنی مانند فراوانی کلمات، میتواند دسته بندیهای مناسبی را انجام دهد.
سیستمهای توصیهگر
KNN در سیستمهای توصیهگر برای پیشنهاد محصولات یا محتواهای مشابه به کاربران استفاده میشود. به عنوان مثال، در فروشگاههای آنلاین میتوان با استفاده از KNN، محصولاتی که مشابه محصولات خریداریشده توسط کاربران دیگر هستند را پیشنهاد داد.
تشخیص ناهنجاریها
KNN در تشخیص ناهنجاریها و کشف الگوهای غیرمعمول در دادهها مؤثر است. این کاربرد در امنیت شبکه برای شناسایی حملات سایبری، در بانکداری برای کشف تقلب و در صنعت برای شناسایی نقصهای تولید مورد استفاده قرار میگیرد.
پزشکی و بیوتکنولوژی
KNN در تشخیص بیماریها و تحلیل دادههای پزشکی کاربرد دارد. با تحلیل ویژگیهای بیماران و مقایسه آنها با دادههای تاریخی، میتوان بیماریها را تشخیص داد یا درمانهای مناسب را پیشنهاد کرد. همچنین، در تشخیص الگوهای ژنتیکی و تحقیق در زمینه ژنومها استفاده میشود.
بازاریابی و تحلیل مشتریان
KNN در تحلیل رفتار مشتریان و تقسیمبندی بازار کاربرد دارد. با تحلیل دادههای مشتریان، میتوان الگوهای خرید را شناسایی کرد و پیشنهادهای شخصیسازیشده ارائه داد. همچنین، این الگوریتم میتواند در تحلیل نرخ ترک مشتریان و پیشبینی رفتار آینده آنها مفید باشد.
پیشبینی سریهای زمانی
KNN در پیشبینی سریهای زمانی، مانند پیشبینی فروش، تحلیل روندهای اقتصادی و پیشبینی ترافیک وب سایتها، مورد استفاده قرار میگیرد. با استفاده از دادههای تاریخی و تحلیل نزدیکترین همسایهها، میتوان مقادیر آینده را پیشبینی کرد.
مزایا و چالشهای الگوریتمهای نزدیکترین همسایه (KNN) چیست؟
مزایا
- سادگی پیادهسازی: KNN یکی از سادهترین الگوریتمهای یادگیری ماشین است و نیاز به یادگیری یا آموزش پیشین ندارد. این ویژگی باعث میشود که برای مسائل ساده و سریع، انتخاب مناسبی باشد.
- عملکرد خوب در دادههای کمبعدی: در فضاهای ویژگی با تعداد کمی ویژگی، KNN عملکرد خوبی دارد و معمولاً دقت خوبی ارائه میدهد.
انعطافپذیری در طبقهبندی غیرخطی: KNN قادر به مدلسازی و طبقهبندی الگوهای غیرخطی است. این به این معنی است که میتواند با الگوهای پیچیدهتر و غیرخطی مانند خمیدگیها و دورانها مقابله کند. - کاربرد در مسائل غیرمتوازن:
- در مسائلی که دادههای یک کلاس نسبت به دیگر کلاسها نسبتاً کمتر هستند (مسائل غیرمتوازن)، KNN میتواند عملکرد خوبی داشته باشد.
چالشها
- حساسیت به مقیاس: KNN حساس به مقیاس دادهها است؛ به این معنی که اگر واحدهای اندازهگیری ویژگیها متفاوت باشند، نتایج ممکن است تحت تأثیر قرار گیرند. برای رفع این چالش، نیاز به استانداردسازی دادهها قبل از استفاده از KNN وجود دارد.
نیاز به محاسبات زیاد: برای پیشبینی برای هر نمونه جدید، KNN باید فاصله آن را با تمام نمونههای موجود در مجموعه داده محاسبه کند. این محاسبات زیاد در مجموعه دادههای بزرگ ممکن است به کندی و مصرف حافظه بیشتر منجر شود. - انتخاب مناسب K: انتخاب مناسب مقدار K برای هر مسئله خیلی مهم است. K انتخاب شده باید به گونهای باشد که دقت مدل بهینه باشد و از بیشبرازش یا کمبرازش جلوگیری شود. برای این منظور، نیاز به استفاده از تکنیکهای اعتبارسنجی متقابل و تنظیم K مطلوب وجود دارد.
- عدم امکان تعیین مدل و قانون تصمیم گیری: KNN یک الگوریتم خطی نیست و به عنوان یک الگوریتم پارامتریک، مدل خاصی را نمیسازد. این مسأله ممکن است به معنای عدم امکان ارائه قانونی واضح برای تصمیمگیری باشد، که در برخی حوزهها به مشکل تبدیل شود.
نقش الگوریتمهای نزدیکترین همسایه (KNN) را در زندگی روزمره
الگوریتم نزدیکترین همسایه (K-Nearest Neighbors یا KNN) در زندگی روزمره در بسیاری از زمینهها به طور مستقیم و غیرمستقیم تأثیرگذار است. این الگوریتم به دلیل سادگی پیادهسازی و قابلیتهای متنوع خود در بسیاری از فعالیتهای روزانه و فناوریهای پیشرفته تأثیر گذار است:
سامانههای تشخیص چهره و شناسایی اثر انگشت
در دستگاههای مدرن مانند تلفنهای همراه و دستگاههای حفاظتی، KNN برای تشخیص چهره و اثرانگشت استفاده میشود. این الگوریتم با مقایسه الگوهای چهره یا اثرانگشت کاربر با الگوهای ذخیره شده در پایگاه داده، کارایی بالایی در شناسایی افراد دارد.
سیستمهای توصیهگر در خرید آنلاین
در وبسایتهای خرید آنلاین، KNN برای پیشنهاد محصولات مشابه به مشتریان استفاده میشود. این الگوریتم با تحلیل سابقه خرید و علاقهمندیهای هر کاربر، محصولاتی را که احتمال خرید آنها بر اساس تاریخچه خرید کاربر بالاست، به وی پیشنهاد میدهد.
فیلترسازی ایمیلهای اسپم
در سیستمهای ایمیل، KNN به عنوان یک فیلتر اسپم مورد استفاده قرار میگیرد. این الگوریتم با تحلیل متن ایمیل و مقایسه با الگوهای ذخیره شده از ایمیلهای اسپم، ایمیلهای غیرمطلوب را تشخیص میدهد و جلوی ورود آنها به صندوق پستی کاربران را میگیرد.
تحلیل و پیشبینی مسائل مختلف
KNN در زمینههای مختلف از جمله زندگی روزمره مانند پیشبینی فروش، ترافیک، و هواشناسی نیز کاربرد دارد. این الگوریتم با تحلیل الگوهای زمانی یا مکانی مثل رفتار رانندگان یا تغییرات آب و هوا، میتواند پیشبینیهای دقیقی ارائه دهد که در تصمیمگیریهای روزمره مفید باشد.
درمان و پزشکی
در پزشکی، KNN برای تشخیص بیماریها بر اساس ویژگیهای بیمار استفاده میشود. این الگوریتم با تحلیل دادههای پزشکی و تاریخچه بیماریها، میتواند به پزشکان در تصمیمگیریهای درمانی و پیشبینی پیشرفت بیماریها کمک کند.
با توجه به این کاربردها، KNN به عنوان یکی از الگوریتمهای اصلی در یادگیری ماشین و پردازش دادهها، نقش مهمی در بهبود کیفیت خدمات و تصمیمگیریهای هوشمند در زندگی روزمره دارد.

پیگیری اخبار فناوری و اطلاعات
ایرانتک یکی از شرکتهای معتبر و فعال در حوزه هوش مصنوعی و فناوریهای وابسته به آن است. شما عزیزان در صورتی که علاقهمند به پیگیری این اخبار و کسب اطلاعات بیشتر در این حوزه هستید، کافی است در سایت ایرانتک به صورت روزانه آن را مطالعه کنید!
کلام پایانی
الگوریتمهای نزدیکترین همسایه از جمله الگوریتمهای یادگیری ماشین است که با وجود سادگی و قابلیتهای متنوع، KNN در مجموعه دادههای بزرگ و پیچیده ممکن است نیاز به بهینهسازی داشته باشد تا عملکرد بهتری ارائه دهد. انتخاب مناسب K و استفاده از تکنیکهای پیشپردازش دادهها نیز از عوامل مؤثر در کارایی این الگوریتم هستند. با در نظر گرفتن مزایا و چالشهای KNN، این الگوریتم میتواند برای مسائل مختلفی از جمله طبقهبندی، پیشبینی، و تحلیل دادهها مفید باشد، اما نیاز به استفاده معقولانه و شناخت دقیق از شرایط مسئله دارد تا به نتایج قابل قبولی برسد. در این مقاله به طور کامل به بررسی اینکه الگوریتمهای نزدیکترین همسایه چیست و چه کاربردی دارد، پرداختیم. شما عزیزان میتوانید سوالات خود را در این زمینه با کارشناسان ما در میان بگذارید.
سوالات متداول
1. الگوریتم KNN چیست؟
KNN یک الگوریتم یادگیری ماشین است که بر اساس اصل نزدیکترین همسایهها عمل میکند؛ به این معنی که برای هر نمونه جدید، با محاسبه فاصله آن از نمونههای آموزشی، بیشترین تعداد همسایههای نزدیک را انتخاب کرده و بر اساس رأی آنها، نمونه را به یکی از کلاسهای موجود در دادهها تخصیص میدهد.
2. چالشهای الگوریتم KNN چیست؟
از جمله چالشهای KNN میتوان به حساسیت به مقیاس دادهها، نیاز به محاسبات زیاد برای پیشبینی، و انتخاب مناسب مقدار K اشاره کرد. همچنین، این الگوریتم در مجموعه دادههای بزرگ ممکن است به مشکل کندی و مصرف حافظه بیشتری منجر شود.
3. کاربردهای الگوریتم KNN چیست؟
KNN در زندگی روزمره در مواردی مانند سیستمهای توصیهگر، تشخیص اشیاء در تصاویر، تحلیل دادههای زمانی، فیلترسازی ایمیلهای اسپم، و تشخیص بیماریها در پزشکی مورد استفاده قرار میگیرد.